External Monitoring
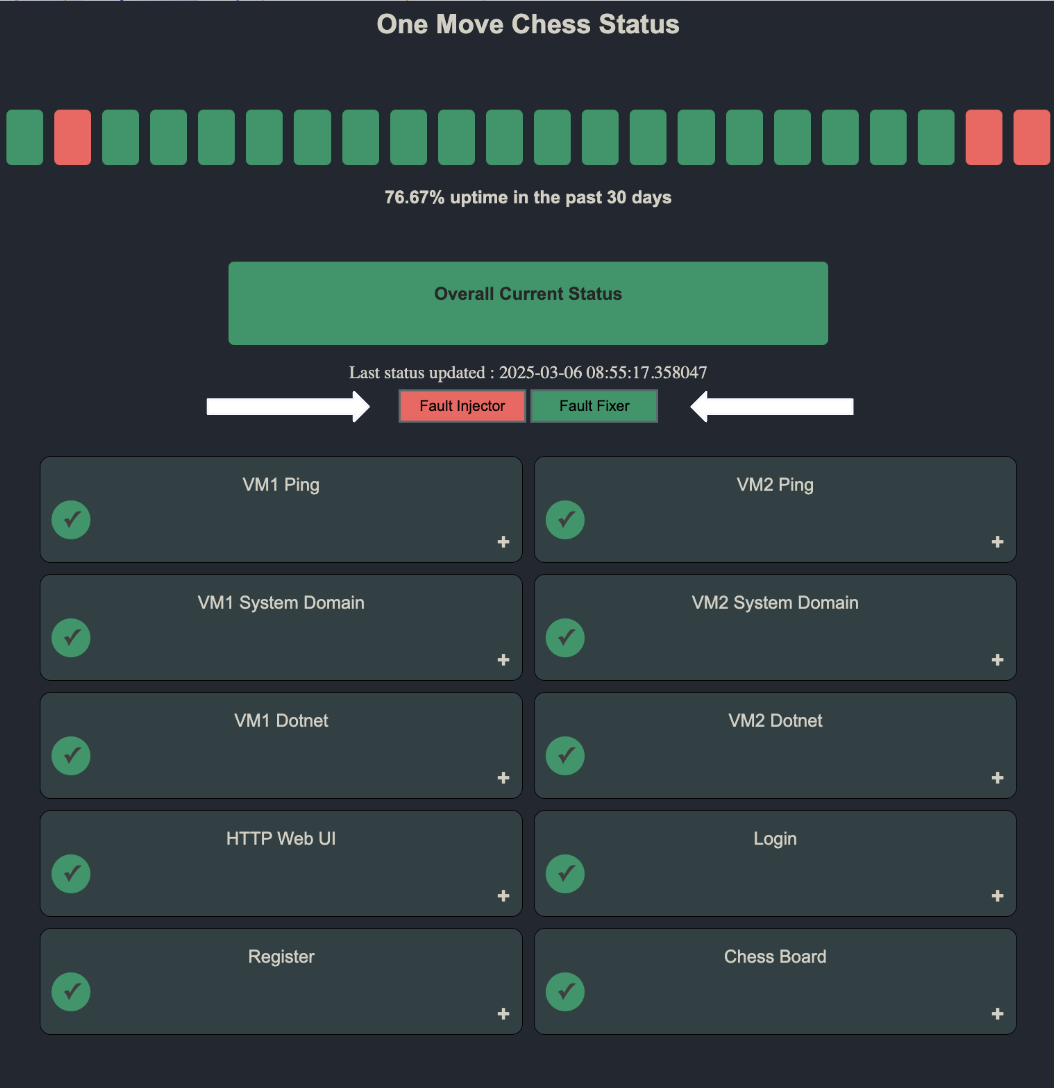
Status Page
Link to Github repository: Status Page Github
The status page provides real-time updates on the game's performance and availability.
Our status page is an essential component of chaos engineering. Monitoring our service's readiness and availability is crucial, as it improves our ability to recover in the event of a failure or incident. Moreover, when deliberately injecting failures, it is ideal that the services are already in a healthy state. The status page is a great tool for double-checking that everything is running well before simulating disruptions.
Here is a demo of how the Selenium bots register, log in, and make a move to simulate the user experience and ensure all of these components are functioning correctly:
Fault Injection
Fault injection is a critical component of chaos engineering because it allows us to proactively test system resilience by deliberately introducing failures and observing how the system responds. The goal is to simulate both software and hardware faults to assess our system’s ability to recover while also testing the effectiveness of our monitoring tools. In our project, we implemented several fault injections, including killing the API on VM 1, shutting down the Web UI on VM 2, and renaming the database on VM 1 to simulate real-world disruptions. By doing so, we ensured that our system could detect and respond to failures effectively. However, injecting faults alone is not enough—we also implemented a fault fixer, which included mechanisms to restart the API on VM 1, restart the Web UI on VM 2, and locate and restore the database name on VM 1 if it still existed. This automated recovery process not only tested our ability to handle unexpected failures but also reinforced the importance of having robust monitoring and self-healing mechanisms in place to maintain system reliability. We included fault injection and fault fixer buttons on our status page, so that we could introduce failures and recover from them with the click of a button.
Notifications
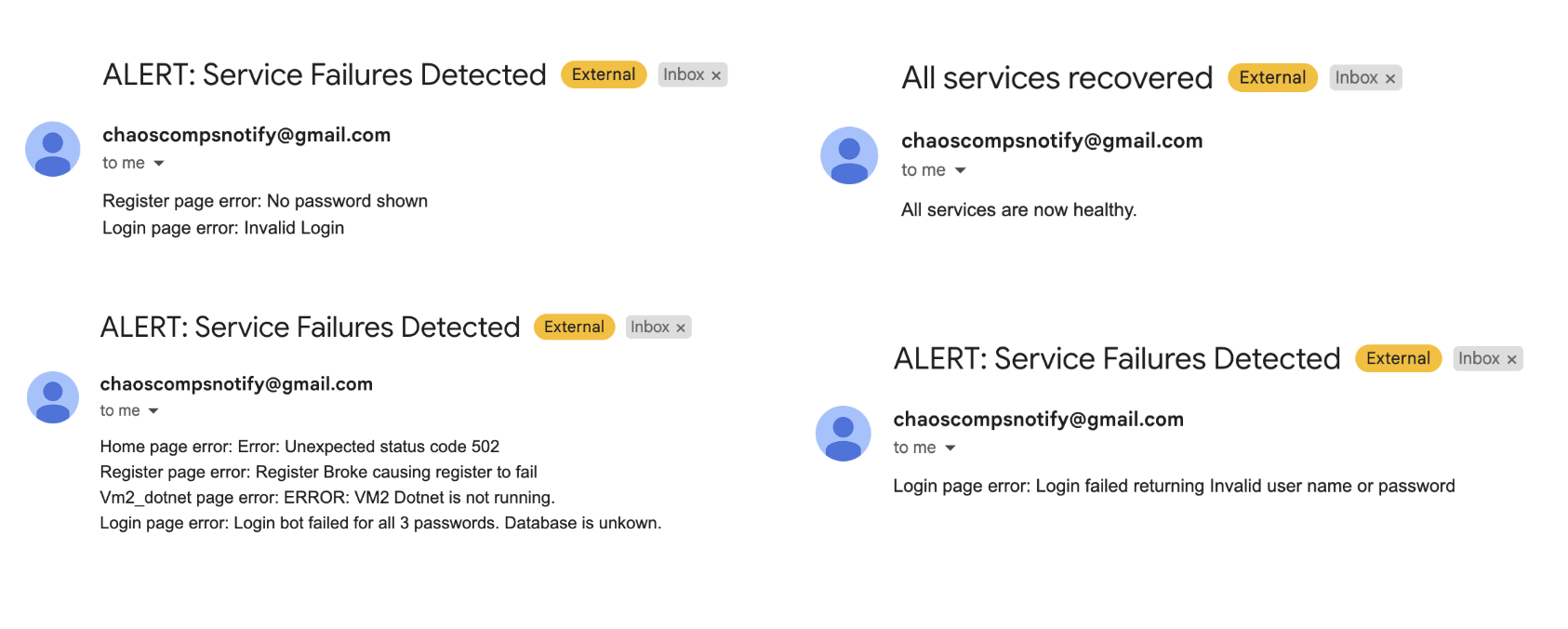
As developers, we need to know immediately if something is wrong. We can’t just rely on someone randomly checking the status page to see if a component is down. At the same time, we don’t want to assign someone to constantly monitor the status page. To address this, we developed a system that sends notifications whenever an issue arises.
We modeled this system after the DevOps or engineer-on-call approach used by real software companies. In this system, one team member is designated as the on-call engineer at a time, with the responsibility rotating among the team. When an issue occurs, the on-call engineer receives a notification and must respond accordingly to resolve the problem as quickly as possible.
To implement this, we coded a system to send email notifications via an SMTP server. These notifications provide immediate alerts when a component is down and also notify us when the system has returned to a healthy state. Below are some examples of emails we have received: