Loquela: Topic Modeling of Latin Text
Carleton College Computer Science Comps 2018

Carleton College Computer Science Comps 2018

Topic Modeling of Latin Text
Topic modeling is a method of statistically identifying abstract topics that are present throughout a set of documents by grouping together words in those documents that are related. For our Computer Science Comps, several members of the Carleton College History department asked us to create a topic modeling algorithm that would work on Latin texts. The result was Loquela.
Loquela has 2 parts: the algorithm, and the application. The algorithm runs topic modeling on any Latin or English corpus, and allows the user a great deal of freedom in building a model using parameters that are appropriate to their corpus. The application allows the user to explore the results of that algorithm in the context of the corpus through several different data visualization tools.

Latent Dirichlet Allocation
After researching several different approaches to topic modeling, we decided that Latent Dirichlet Allocation, or LDA, was the best algorithm to implement for our purposes. LDA is unsupervised (latent) but allows the user to manipulate the number of unique words within a topic or unique topics within a document, based on a set of hyperparameters, or Dirichlet priors.
The output of the algorithm is groups of words, called "topics," that are presumed to be semantically linked in the text.
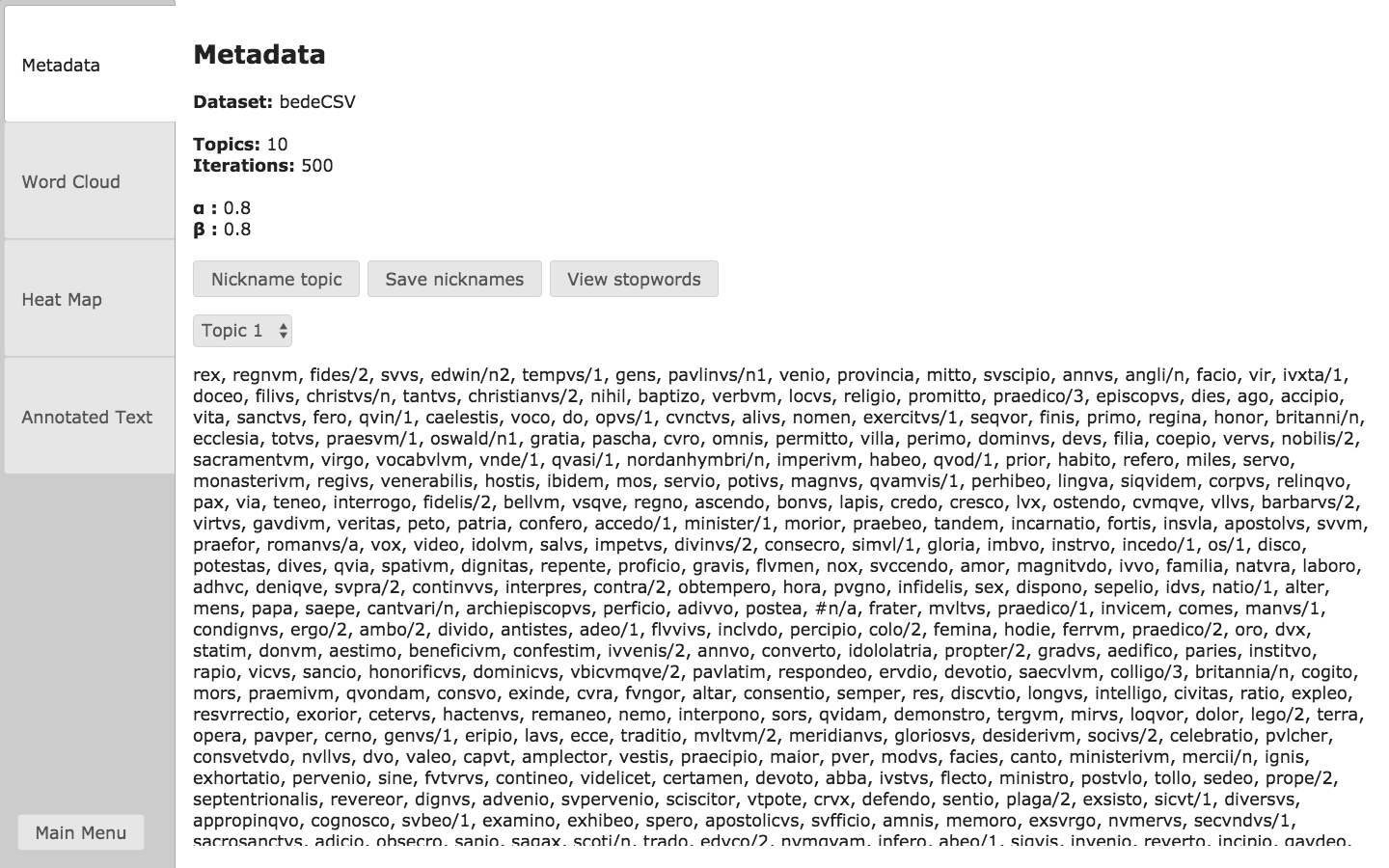
Visualizing Topic Models
The Loquela application allows users to explore the results of their generated topic model. In addition to basic metadata information, Loquela includes three visualization tools: word clouds, heat maps, and an annotated text.
These tools work together to place the topic model back into the context of the original corpus, allowing comparison of both words within a topic, and topics within a document. With Loquela, the user can easily interact with and inspect the data yielded by LDA.
digital humanists in action
Youngest, most mathematical, most enamored of colorful chalk.
Computer Science/English Major. Enjoys digital humanities projects and short-ish walks on the beach.
Filmmaker, fanatic of text and audio generators, music collector. Enjoys photography and digital manipulation.
Tabletop gaming enthusiast and overall nerd. Enjoys coding in JavaScript for some reason.
Latinist, Musician, Mead-drinker
Medieval and Renaissance Studies minor
air-speed velocity (unladen): unknown
CS/Music/French. Likes Python, piano, pooches, parakeets, interrupting alliteration, participles, parmesan.