Data Structures
One of the early challenges we faced when developing our recommender system was choosing data structures that would allow easy and efficient access to our large data sets. This problem became even more important when we started using the Netflix data. With over 100 million ratings, it was important to optimize for both speed and memory usage. Eventually we tried two different techniques for storing our data: a relational database and a hash-table based class called MemReader.
Database
One of the most natural ways to store a large amount of data is a relational database management system (RBDMS). These software packages use sophisticated data structures and algorithms to access data stored on disk. Programs can access the database using the structured query language (SQL), which supports a wide variety of queries. For example, it is easy to find all of the users who have seen a certain movie or to find the movies that two users have both seen. This flexibility led us to create a MySQL database for the Netflix and Movielens data sets. The schema is shown below:
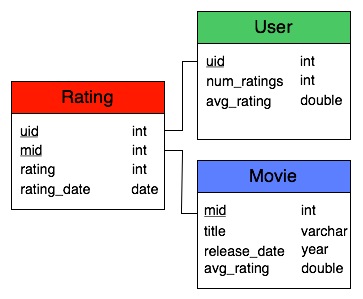
Note that we precomputed the average rating for each movie and user for performance reasons. Ultimately, performance considerations led us to abandon the database. While most database systems are highly optimized, they still store most of the data on hard disk, which is very slow to access. Additionally, we discovered that MySQL did not implement some of the high performance algorithms we needed for complex queries. Since recommendations using the Netflix data can require millions of database queries, we had to find a different approach
MemReader
(This data structure was proposed on Netflix prize forum by user "voidanswer." It appears to be impossible to link directly to specific posts, but their code is available at http://www.freelive.org/javaflix.zip. Our code is significantly different than this version.)
The main reason that database access is so slow is that it accesses data from the hard disk. We can avoid this bottleneck by storing all of the data in memory. Though the Netflix data set is very large, it can be stored in less than two gigabytes if managed carefully. MemReader is designed to provide such access.
In order to provide fast access, we store each rating in two hash tables, one indexed by uid and one indexed by mid. To store the ratings themselves, we observe that neither the uid nor the mid take more than 24 bits to store. Since an int in Java is 32 bits, we shift the uid or mid over to the upper 24 bits and store the rating in the lower bits. Since bitwise operations are very fast, this technique reduces memory usage without slowing down access very much. A diagram of the user-to-movie hash table is shown below. Additionally, we store a hash table containing the number of movies rated by each user and the sum of the ratings for each user (and similarly the number and sum of ratings for each movies). This allows for efficient computation of averages and the ability to add users to an existing MemReader object.
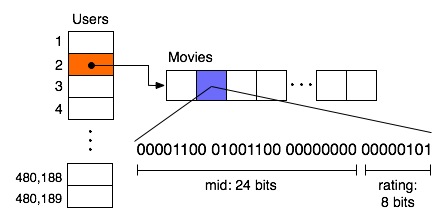
MemReader has proved very effective for the Netflix data set, and we have extended it to work for both the Movielens and transcript data. The MemReader interface does not offer the flexibility of SQL, but we have implemented our own algorithms for specific queries and have seen a significant speed improvement.