Replication of Counterfactual Fairness in Text Classification through Robustness
ABSTRACT
Deep learning is a common method to create models for the binary task of classifying comments on online forums as toxic or nontoxic. While these models have good performance overall, they often have an inherent bias to classify sentences containing certain identities e.g. "gay", as toxic. To solve this problem, a method has been proposed to both quantify this phenomenon and counteract this bias. Namely, it proposes the Counterfactual Token Fairness metric and the Conterfactual Logit Pairing loss function. We reimplement the methods of this proposal and evaluate our experimental results against theirs. We also test the robustness of the results with regards to model complexity and the dataset splits used. Our final results approximate their results in terms of the general trends, however there are discrepancies in our values where Counterfacutal Logit Pairing underperforms and augmentation overperforms. This provides evidence that their methodology and results are overall robust but may be somewhat limited in the scope of problems.
TEXT CLASSIFICATION BY MODEL
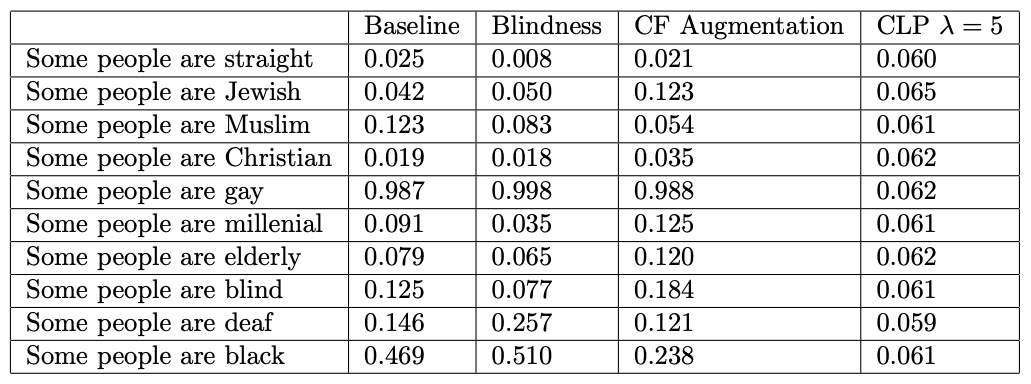
Some example sentences and their toxicity prediction by different models. 0 is predicted to be nontoxic and 1 is predicted to be toxic. “gay” and ”black” are held-out identities, all other identities are part of the training split.