Dialogue Manager
Decision making, conversation flow, and follow-up questions
Other parts of the project
Think before we speak
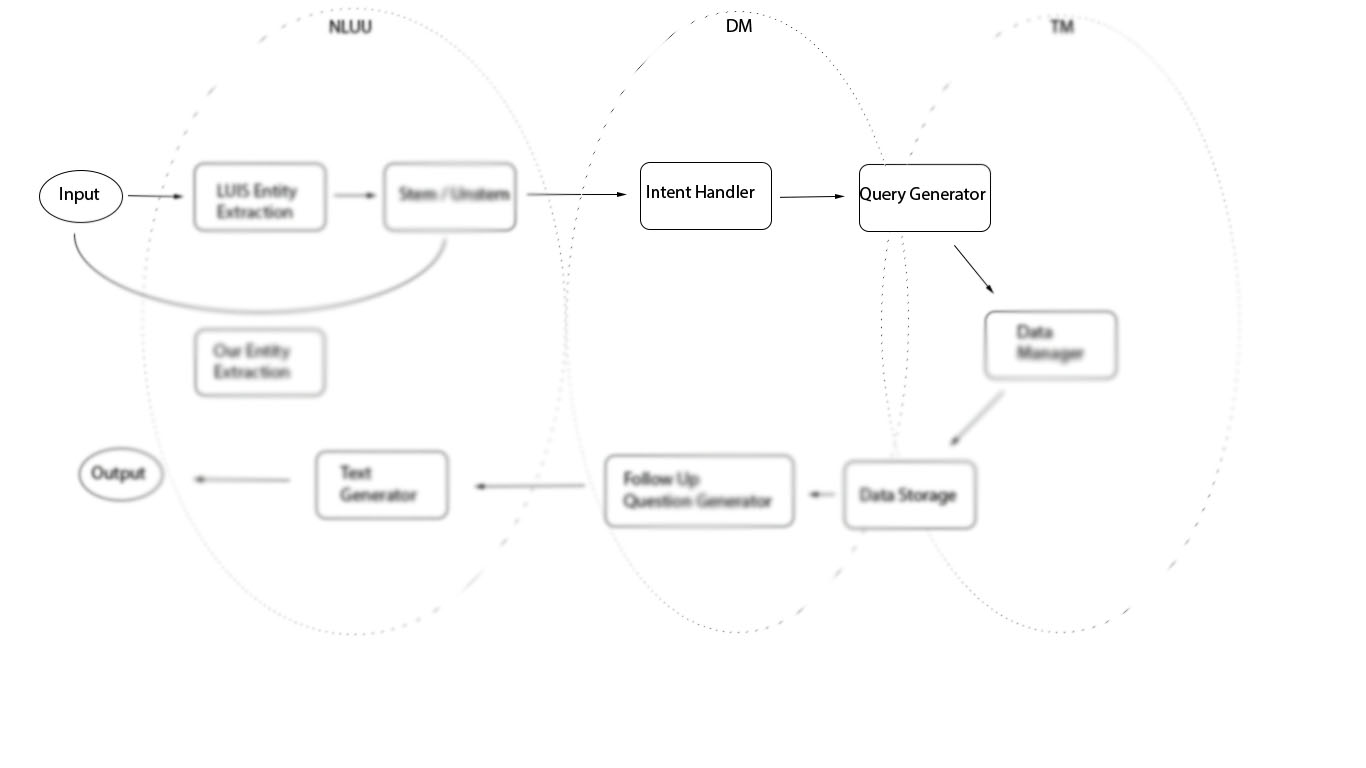
This is the real brains of the program in terms of conversation decision making and handling. A number of files in this folder are domain objects to help us group piece of information, such as courses and students. Every time the student asks about particular classes, each is filled out and manipulated using a Course object. Each conversation is given a Student object that holds information about previous things we have learned about the student as well as courses we've talked about. These are relatively brainless collections of data that do not provide functionality, except for a pretty way of printing to the terminal. The two main files in this domain are Conversation.py and decision_tree.py.

Conversation
This file starts the conversation, enters a conversational loop, and handles all of the decision making given the current intent and the past context in which a particular utterance is made. For instance, "Put me in CS111" will give back the same ScheduleClass intent as before, and Conversation will determine that CS111 is a course, query the database (via TaskManager) to fill out the information, and add it to the student's schedule.
More interestingly, we handle more complicated interactions that last longer than a single input/output. For instance, say the client is interested in rocks. We query the database about classes that may have something to do with rocks and suggest 3-5 courses for the client to consider. They may wish to register for one of those courses, but colloquially referring to a listed course by its title may sound irregular. One would instead say "Register me for the 2nd one". Being able to understand the intent and the context is integral to producing the correct behavior. This is what Conversation attempts to do.
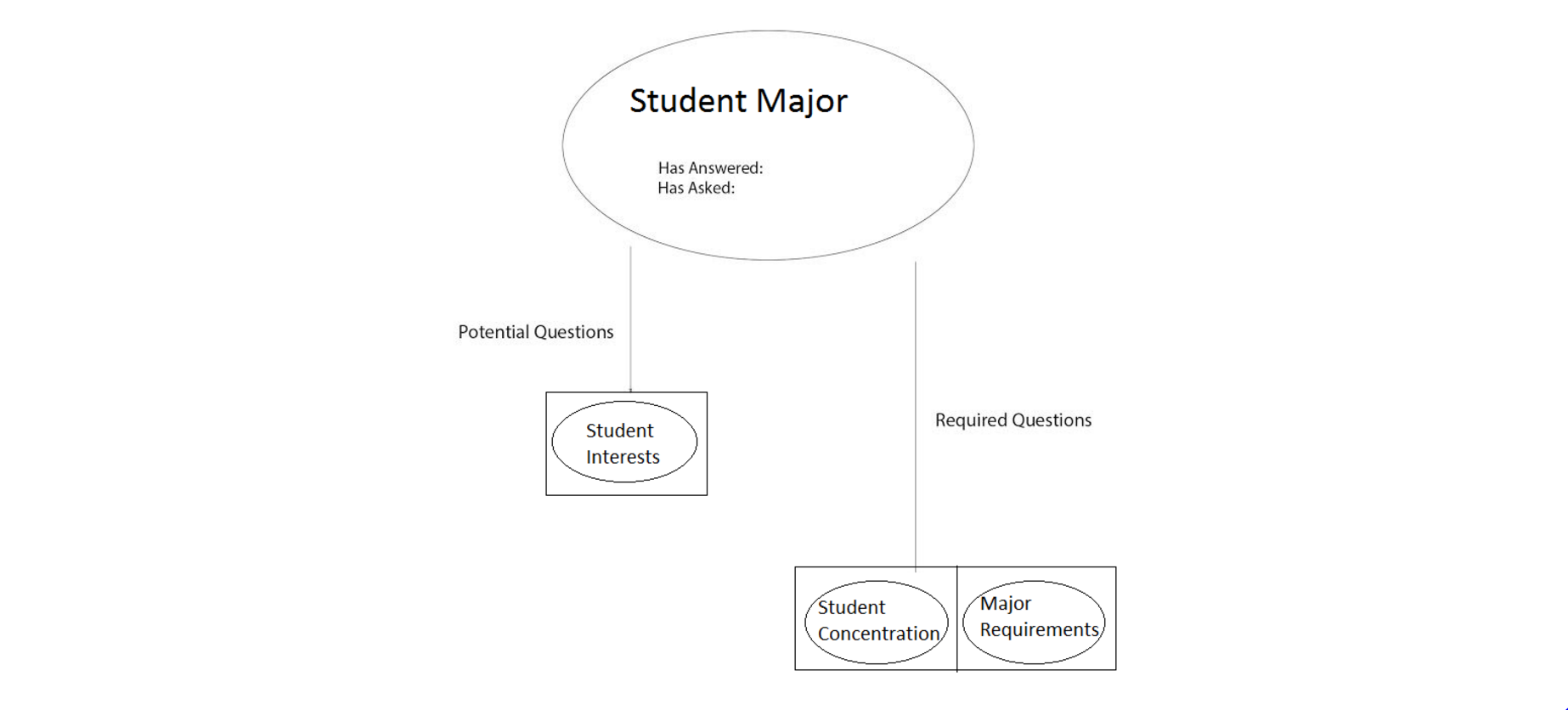
Decision Tree
The decision tree is a tree of nodes that guide the conversation. Each node is linked to a single userQuery object, which correspond to one of nearly forty responses we might give to a user. We ask leading questions, respond to deviations in the trajectory in the conversation made by the client in intelligent ways that still allow us to accomplish our objective of registering the client for 3 courses. The order in which we ask questions and determining how questions have been answered or deflected is handled here.
We knew that our eventual goal was to get the student to register for a course, and the tree is built around that fact. We have constructed a series of connections for each node that are dependent on whether or not the user answered the question. This allows a user to control the flow of the conversation if they so choose. We check what information we already have saved in order to ensure we don’t ask a question we already know the answer to. We also try to avoid asking questions we have already asked, unless it is a question worth repeating. By checking for both of these things, our tree allows us to push the conversation in a sensical and practical way that furthers our goal of recommending courses.
Additionally, we are able to make general assumptions on the direction of the conversation by implementing Paul Grice's Maxims of Conversation, which can be seen here. While these maxims allowed us to make assumptions when dealing with situations when either the student did not know an answer to our question, or the student did not help us decide the direction of the conversation. In the future, we could implement a different theory of conversation by David Traum in his paper A Computational Theory of Grounding in Natural Language Conversation. His paper uses a complex probabilistic transition model to determine the next kind of response in a conversation.