|
A Tour of TITAN
The original idea of the TITAN project was to create a self-learning firewall--that is, a firewall that would learn its traffic-regulating rules on its own, and additionally implement them. This project evolved slightly, and we now have a firewall/router that is good at detecting anomolous traffic, and will implement rules to block this traffic (as well as known bad traffic).
TITAN really has 6 main parts to it.
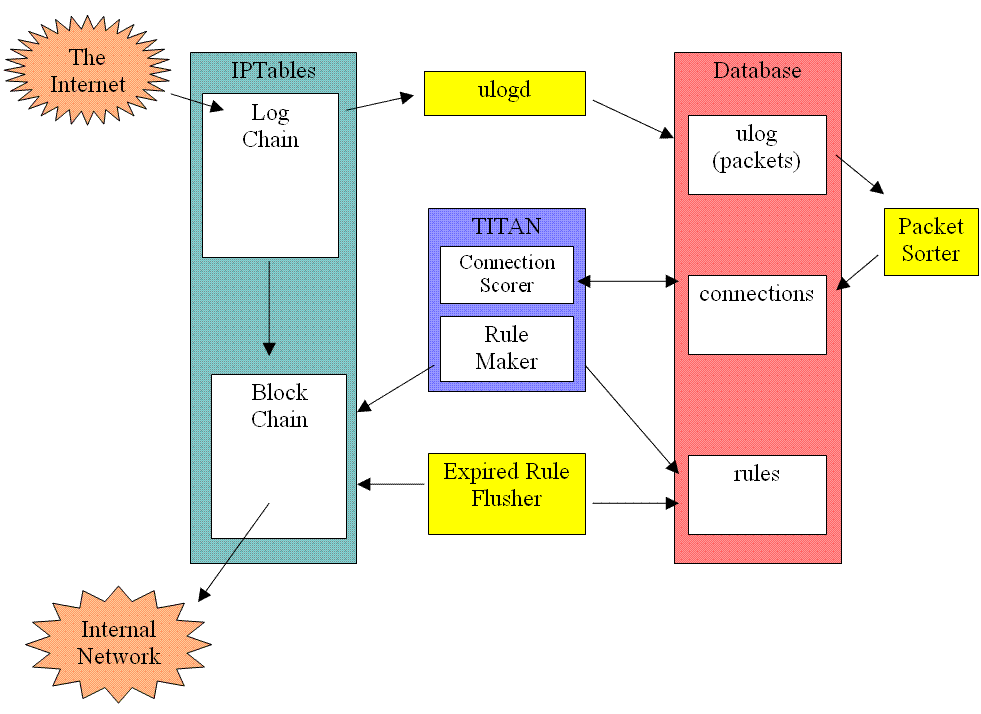
- First is IPTables. This is not a component we wrote (coded), but is rather a built-in part of the Linux operating system. We use this tool to log all the computer network traffic coming through our firewall, and also to actually do the blocking of traffic we deem to be dangerous.
- The second component is ulogd. This is also a stand-alone component that we did not write. Its job is to take packets from IPTables and shove them into our database.
- The third component is the database. For this we used MySQL. We configured it to have one database (we called it "ulog") and 3 tables: ulog, connections, and rules. The ulog table is where we store the raw packet data. The connections table is where we have a list of all the connections we know about. Finally, our rules table is where we keep a list of the active rules that should be in effect on our firewall, blocking traffic from a source.
- A fourth component to be aware of is our packet sorter. Its sole job is to take packets from the packets table in the database and group them into connections, which it puts back into the connections table in the database.
- We have an "expired-rule-flusher" component. This aptly-named piece of the puzzle is checking whether rules have expired from the rules table in the database, and if so it is deleting them from IPTables so that IPTables is no longer blocking traffic that it shouldn't be. This is because there are no "timeouts" on rules in IPTables, so we had to make a way to do this on our own.
- Finally, we have our master component that is tying many of these pieces together. We call this master component TITAN, just like the name of the project. At startup, TITAN reads in to memory a bunch of seed connections from the database. Then, as new connections are added to the connections table in the database, TITAN scores these new connections against the connections it has in memory. It determines the score for a new connection thus: First, the distance to the "closest" connection is determined by looking at certain attributes of the connections, and comparing how closely they match up. If the distance is determined to be very near a previously known connection, the new connection gets a score very close to that previously known connection. Thus, if the previously known connection had a good score (high -- close to "1" in our implementation) the new connection gets a high score. If the old connection had a low score (i.e. it was known to be a "bad" connection, close to "0" in our implementation), the new connection also gets a low score. However, if the distance to the closest connection is determined to be fairly far away, the new connection a lower score.
If the score of a connection is below a certain threshold (.5 in our implementation), a new thread is spawned by TITAN to create a blocking rule for the connection. The rule is added to the database and also to IPTables.
This scoring scheme has the effect of giving our firewall a kind of "default deny" policy. If a connection doesn't match up to any previously observed network traffic (it is anomolous), we choose to block it. The only way connections can pass unhindered through our firewall is for them to match up closely enough to previously known connections in enough ways that we decide they're benign.
A large part of this firewall working correctly rests on having good seed data. We got a large chunk of seed data from DARPA, who took tcpdumps of a lot of network traffic and scored each connection manually. We translated their data to work for our project, but the greatest portion of the work was done by DARPA. Here is the website where we found this data.
The connection scoring also rests heavily on selecting appropriate weights for the attributes we choose to consider. If the weights are chosen poorly, the scores won't accurately reflect the intent of the connections at all, and thus the firewall won't function optimally. More on this issue is discussed on our project extensions page (link at the top of this page).
|
| |