Project Overview
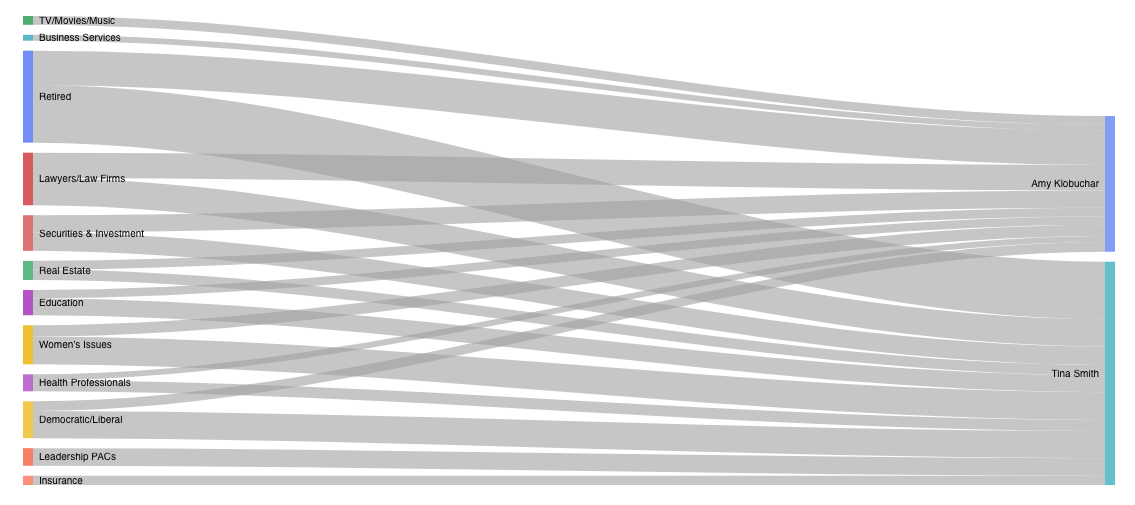
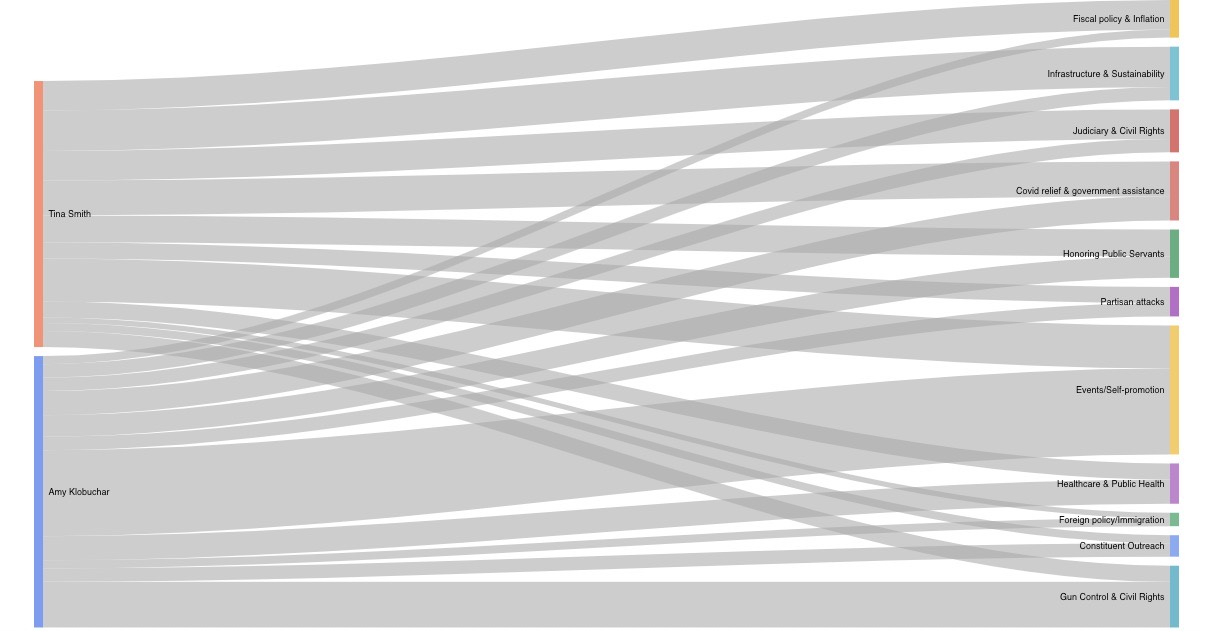
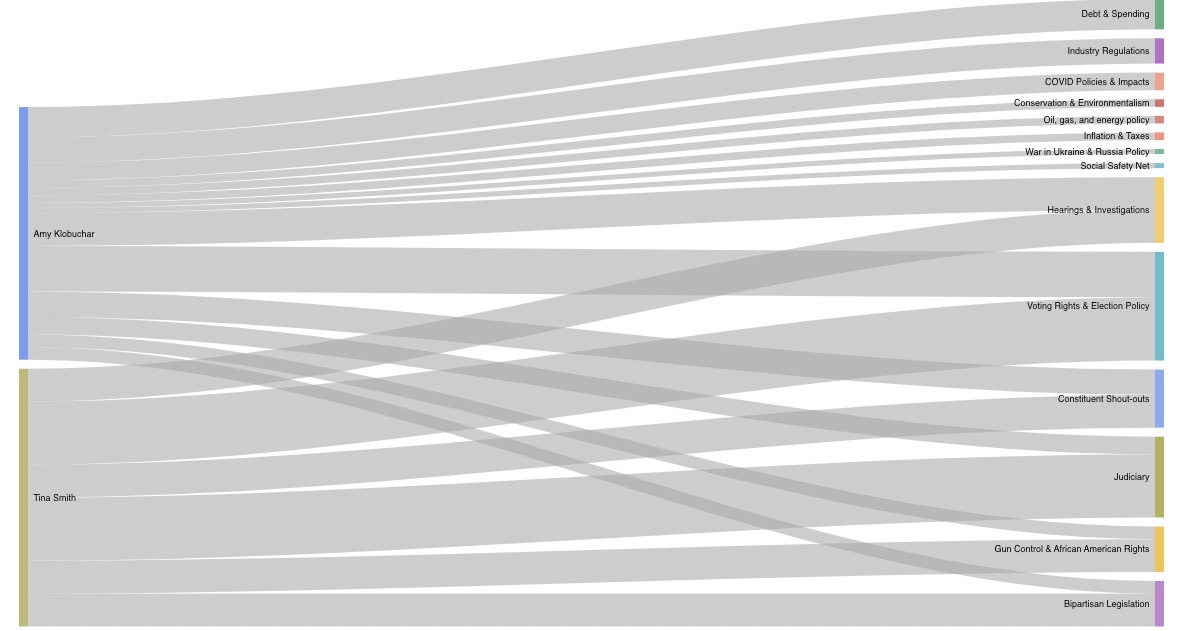
FollowTheMoney is a web application that enables exploration of the relationships between funding sources and speech topics for members of the 117th United States Congress. These relationships are visualized in the form of Sankey diagrams, which the flows of money from donating industries to congresspeople and the flows of speech from congress people to topics. FollowTheMoney uses data on campaign funding broken down by industry gathered from OpenSecrets, statements made on the floor of Congress collected from the Congressional Records, and tweets for each congress person pulled from Twitter. To extract and quantify the topics contained in the statements and tweets, we used a Latent Dirichlet Allocation (LDA) topic model, assigning each document to a particular topic. We hope that FollowTheMoney's intuitive, simple interface can help a broad audience understand better how campaign contributions influence what politicians talk about.
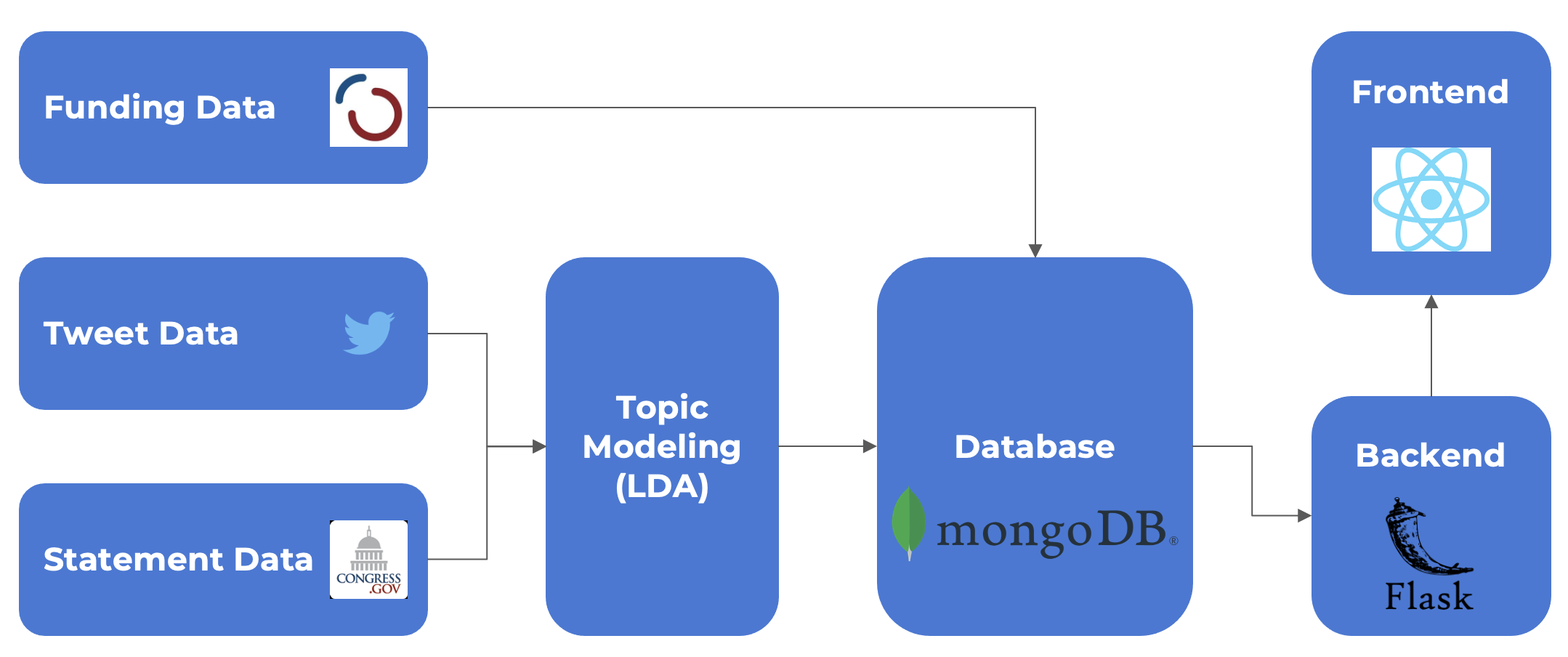
Figure 1: Project Workflow